This semester, I took a class on Digital Archives and Preservation, taught by the inestimable Dr. Pat Galloway. One of distinctive things about this course is that students are assigned into teams that spend the semester tackling a real digital preservation problem. This semester, groups worked with materials from the School of Information and from the Videogame Archives at the Briscoe Center for American History. Each group researched the technical and policy challenges of their collection, worked with stakeholders, ensured the long-term stability of their materials, and ingested them into a digital repository. So not only do we learn about the theoretical bases of digital archiving, we also have the chance to gain practical experience and contribute to the actual preservation of our digital heritage.
I was part of a group that was tasked with preserving the School of Information’s website, along with my classmates Jarred Wilson, Laura Vincent, and Kathryn Darnall. The iSchool’s website had been undergoing a major re-design, and the new version of the site launched in March. This was a perfect time to archive the website, as it gave us a natural “cut-off” date for what version of the site to preserve. The iSchool recognizes the value of the website, both as a record of the school’s official policies and as a historical document providing evidence about the evolution of the field of information studies. We were therefore lucky to have the cooperation of the administration and website administrators in archiving the site. Early in the semester, we began meeting with Sam Burns, the iSchool’s Content and Communications Strategist and the person who has the most direct control of the website. He was an enormous help to us, helping us understand the back-end structure of the site and assisting with many of the more technical challenges we faced over the semester.

From the beginning, our group was interested in moving beyond just crawling the website. Web crawling has become the most generally accepted method of web archiving, and it is a great way to create interactive copies of web records. However, crawling has limitations. There are several kinds of online materials that crawlers can’t capture, including many forms of dynamic and database-drive content. More fundamentally, crawlers only document how a website is displayed in a browser; they capture the experience of an end-user of a site, but not the many pieces that exist behind the scenes to generate the site. Sam encouraged us to think about how we include site administrators in our designated community of users, and that prompted us to re-think the significant properties that we considered necessary for documenting the website. Future administrators of the site might be very interested in knowing how the archived website was built, but the components they would need to study, for example PHP codes, would not be included in a crawled version.
For those reasons, we decided to explore alternative web archiving methodologies, in addition to crawling the site. (I wrote about our struggles with using Web Curator Tool for crawling in my last post.) The solution we decided to attempt was to use a virtual machine to create a fully functional replica of the website. Our goal was to recreate the environment in which the website was run as completely as possible, so that users could interact with the site as it was displayed in a browser and with the component databases and file directories. With Sam’s help, we obtained all of the files used to generate the site from the iSchool’s servers, including HTML and PHP files, copies of databases, images, and other files. We then created a virtual machine using Oracle VM Virtual Box, placed those files inside, recreated the databases, and installed the software that was originally used to run the site, including PHP, an Apache web server, and a MySQL database. After a few challenges and hurdles, we successfully managed to get all of the various components communicating and working together. We then saved the virtual machine as a VMDK file (an open-source format), which we ingested in the iSchool’s DSpace repository, along with the individual component files and a crawled version of the site.
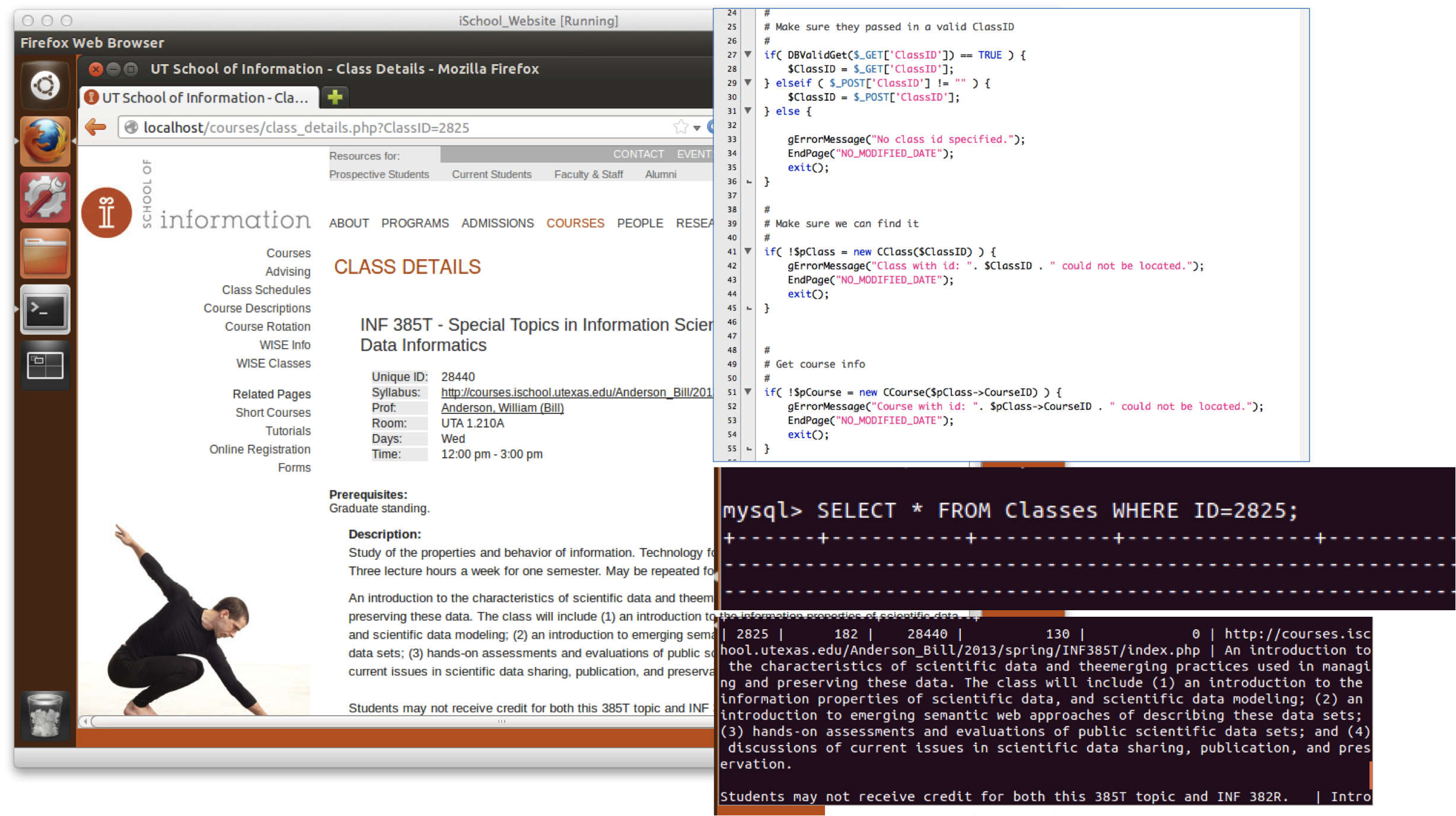
We were very pleased that we were able to get the website up and running within a virtual machine environment, and all of us who worked on the project believe that this is an exciting new method for web archiving. However, we also recognize that there are considerable challenges in using virtualization for web preservation. Obviously, this project was quite time consuming and required considerable commitment not just from the archivists, but also from the site administrators. It remains to be seen if this method can be made scalable, or will be useful only as a boutique solution for high-value websites. Another considerable challenge regards access, privacy, and intellectual property. To recreate the website in the virtual machine, we obtained copies of every file used to generate the website, and almost without a doubt, some of those files include material that should not be publicly accessible for various reasons. We did make some efforts to clean up and redact sensitive information, for example by changing the passwords in the databases to prevent breach’s of the iSchool’s security. However, we were unable to commit the time necessary to granularly examine all of the files. For those reasons, we chose to make the archived virtual machine and individual component files closed in the digital repository. Obviously, though, open access would be much more desirable, and further study would be necessary to determine how to appraise and redact the files to allow that.
Despite these challenges, I am very proud of our work on this project, and excited about the possibilities that virtualization offers for expanding the field of web archiving.
To learn more about this project, download our final report or view the poster we presented at the iSchool 2013 Spring Open House. You can also view the archived website in the iSchool’s digital repository at https://pacer.ischool.utexas.edu/handle/2081/30462.