Hello! I’m back with another edition of “Elliot writes out the process for how I did something, mostly for myself, but puts on the internet in case anyone else finds it useful.” This one started out as one thing (counting percentages of MARC records in a set that contain a given field) and morphed into another thing, as well (use OpenRefine to add labels to LCC class numbers).
I’ve been discussing with one of my colleagues ways to enrich our MARC record for musical scores to improve their searchability in the catalog. One thing that we’re interested in is including more 505 table of contents notes, particularly for collections or anthologies of printed music. There are a lot of reasons that would be nice, but a big one is that collections are one of the main sources in our collection for works by contemporary composers, composers of color, and women composers.
As we figure out if that’s worthwhile and how we might approach it, I wanted to do some analysis of our notated music records to see how many have 505 notes. I wanted to break it down by LCC classification, since we’re thinking that that might be a helpful way of identifying priority areas and chunking the project into manageable pieces. So here’s what I did:
Getting the data
- In Alma, did an advanced search for all physical notated music records, then exported those MARC records.
- There were a total of 12,949 records, which is a lot but manageable for what I was hoping to do.
- Used MarcEdit to export the fields I care about to a tab-delimited file: 001, 245, 050, 090, 505
- Much later in the process, I realized it would have been helpful to include the 035 field at this stage. Whoops.
Processing in OpenRefine and class number cleanup
- Imported the tab-delimited data into OpenRefine
- Created a new column called “TOC?”, where I entered either yes or no based on the presence of a 505 field in the record (using OR’s “Facet by blank” facet)
- Combined call number data from 050 and 090, and do some preliminary cleanup (mostly removing indicators/subfields and stray extra characters from the front)
- At this point, I realized it would have been better to have the call numbers from the holdings records, rather than the bib records, but that would have been more complicated to get out of Alma so I decided to go with what I had. Good enough for this kind of exploratory analysis.
- Used a regular expression to create a new column with just the first part of the call number, up to the first period that comes before a letter (hoping to get just the base classification number)
value.match(/[A-Z]+*\.?\d*).*/).toString()
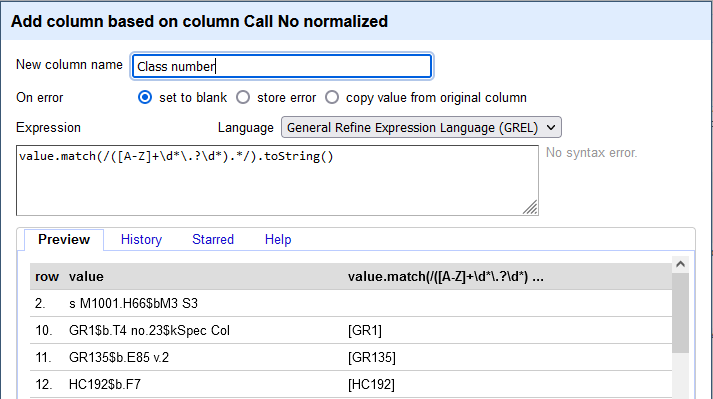
Getting more info about class numbers
- Now I had the basic class number for each record. But I’m not super familiar with music class numbers, so I wanted to include the label for each number. I knew that on our old friend id.loc.gov, you can get data about each LC class in a variety of data formats, and you can construct the URL using the class number itself, e.g. https://id.loc.gov/authorities/classification/ML3551.html. I first tried to work with the JSON versions, but I’m more comfortable with XML, so ended up using the RDF/XML format, e.g. https://id.loc.gov/authorities/classification/ML3551.rdf
- Before making a bunch of URL requests to the Library of Congress, I used OpenRefine’s records mode and blank down feature, to make sure that I only had to make one request for each class number. So only 757 URL requests, instead of 12,949.
- I think I picked up this tip from a Programming Historian tutorial I was using to help figure out this process.

- Okay, now the good stuff: I created a new column in OpenRefine by fetching URLs based on Call No base column, using expression
'https://id.loc.gov/authorities/classification/'+value+'.rdf'. Now I have a column full of XML! - Looking at the RDF/XML, I decided I wanted the <rdfs:label> field that contained the full chain of where this class number fits in the classification hierarchy. The problem is, though, that there are multiple <rdfs:label> elements in the output – so using just plain parseXml().select(’rdfs|label’) wouldn’t work. I want the instance of that element that is directly under the <lss:ClassNumber> element. So I looked at the documentation for Jsoup (I know, what an idea, right?), and figured out I could use
value.parseXml().select("rdf|RDF > lcc|ClassNumber > rdfs|label")[0].toString()to get exactly the element I wanted.- (This makes it sound a lot more straight-forward than it actually was. Imagine lots of flailing around and frantic googling at this stage, particularly when I was trying to use JSON results before switching to XML.)
- Pro-tip that I learned in this process: if your XML elements have namespaces, you have to enter them in the select expression as “rdfs|label”, instead of “rdfs:label”.

- Ta-dah! Now I have a column with the full LCC description for each class number in my dataset. I used fill down in OpenRefine to add the class number and label to all of the rows.
- There were about 7 records where the process didn’t work because the data wasn’t structured normally or the call number was missing from the bib, so I added those manually.
At this point, I thought I might be fancy and do something with pandas (which I’m very much a beginner with) to count the number of records without a 505 per class number. But I decided I knew how to do what I wanted to in Excel, so I just did that instead. 🤷 I used some simple deduping and COUNTIF formulas to get the number of records per class number, and the number in each class number that do not have a 505 field. And it includes the full classification hierarchy label for each number, which is helpful. That allowed me to highlight all of the rows with “Collection” in the classification label, which has already been helpful in pinpointing some class numbers to explore in more depth.
