It’s been a minute since I wrote anything on this here blog, but I was working through a process today that I wanted to document and thought that other folks might be interested in.
This week, a group of coworkers and I were discussing whether there is an LCSH for “Cuban diaspora” (there is not), and whether there should be (we think that might be useful, and might eventually want to work on a proposal). There are a handful of other LCSH terms for “[blank] diaspora”, and I wanted to be able to view them all at once, rather than paging through them individually in ClassWeb. That way I could compare the See From and See Also From references, the public notes, and the works cataloged, to get a sense of what the format and structure of this group of subject headings is. So basically, what I wanted to do was to download a batch of LCSH records in a format that I could open in OpenRefine to examine.
LCSH records are available in a variety of formats from id.loc.gov, so I know the records are there on the web. The records are available in MARCXML, JSON, RDF, and a number of other flavors. I just needed a way to identify the ones I wanted and download them in batch.
Here’s what I ended up doing. As always, I’m sure there are other, probably faster or simpler ways to do this, but this process worked for what I wanted and used tools that I already knew how to use:
- Search LCSH for “diaspora” in id.loc.gov
- Literally copy and paste from the search results into a spreadsheet. There were 55 total, so it was only 3 pages of results that I needed to copy.
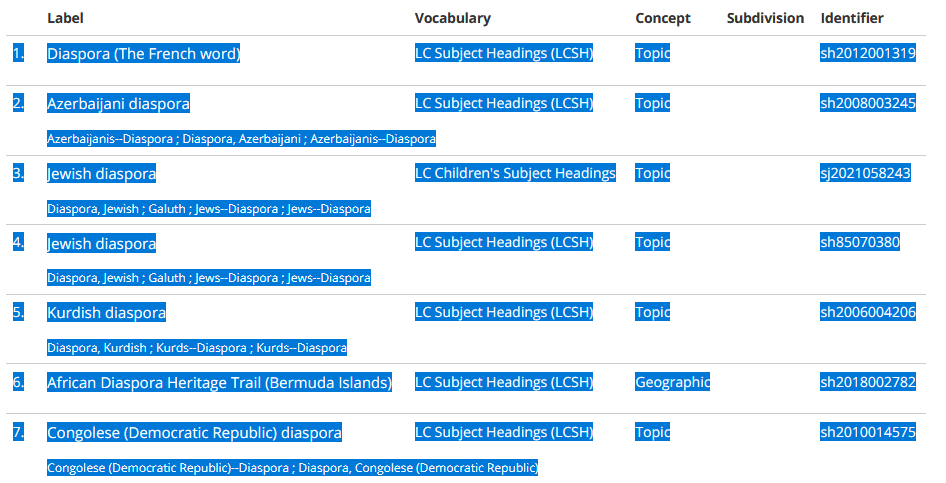
- In the spreadsheet, remove the subjects I’m not interested in, isolate the identifiers (e.g. sh2006004206), and save the list of identifiers as a text file. Now I have a list of all of the identifiers for the relevant subject headings.
- Now the part that took a bit more figuring out: Use curl to download the files in bulk.
in $(cat Desktop/DiasporaSH_ids.txt); do curl -o “Desktop/diaspora/$ID.xml” “https://id.loc.gov/authorities.subjects/$ID.marcxml.xml”; done
Basically, what that does is read the list of identifiers, copies them into a variable ($ID), then runs a curl command using that variable to build the URL and saves the output, in this case as an XML file. I use GitBash as my shell for running commands like this. As usual, it took me some time to figure out how to get the “for” loop to work (it always takes me a while to remember how to structure it properly). And because I use a windows computer, I also had to remove the carriage return characters at the end of the DiasporaSH_ids.txt file, so I’d stop getting an “Illegal characters found in URL” message. I used dos2unix to do that.
- Now I have a folder full of MARCXML files!
- Repeat the curl command for RDF and JSON files, or other formats as needed.
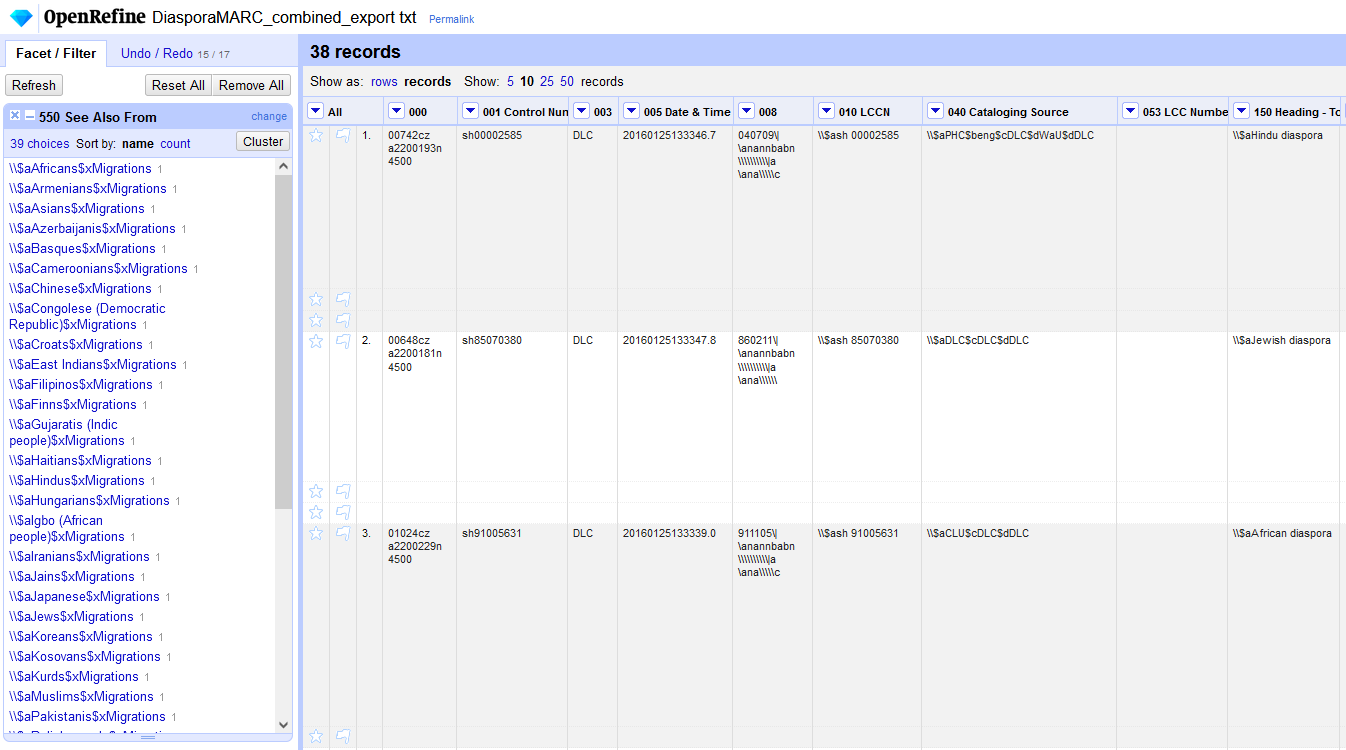
For what I wanted to do today, the MARCXML turned out to be the most useful. I went through a whole process using MarcEdit to convert them into .MRC files and then export the records to tab-delimited text, which I then loaded into OpenRefine. I’m sure another tool could have done that more easily (probably pymarc?), but I knew I could get it done with MarcEdit, and just went with that.
And voila, I had what I wanted!
Wouldn’t it be nice if we could reconcile in Open Refine against the LC headings? Then you could have just used the IDs you got from the copy-and-paste. Then just add columns of interest from the reconcile d values.
Honestly, it didn’t even occur to me to reconcile the headings in Open Refine! Thanks! And if you have the IDs, you don’t even need to reconcile – I bet you could use “Add column by fetching URLs” to pull the JSON or XML directly into OR.